Spark срещу Hadoop: Коя е най-добрата рамка за големи данни?
Тази публикация в блога говори за apache spark срещу hadoop. Това ще ви даде представа коя е правилната рамка за големи данни, която да изберете в различни сценарии.

Тази публикация в блога говори за apache spark срещу hadoop. Това ще ви даде представа коя е правилната рамка за големи данни, която да изберете в различни сценарии.
Този блог ви помага да разберете как да инсталирате и настроите приставката sbteclipse с инструкции стъпка по стъпка за стартиране на приложението Scala в Eclipse IDE.
Тази публикация в блога обяснява защо трябва да започнете с Apache Spark след Hadoop и защо изучаването на Spark след овладяване на hadoop може да направи чудеса за вашата кариера!
Този урок за Apache Drill ви дава цялата информация, от която се нуждаете, за да започнете с машината за заявки на Apache Drill, използване с Hadoop, Big Data & Apache Spark.
Този блог на Spark Hadoop ви разказва всичко, което трябва да знаете за Apache Spark combByKey. Намерете средния резултат на ученик, използвайки метода combByKey.
Apache Falcon е нова платформа за управление на данни за екосистемата Hadoop, която опростява вградената обработка на фуражи и управлението на фуражи в клъстерите на hadoop. Научете как да го настроите.
Този блог на Apache Spark обяснява подробно акумулаторите на Spark. Научете използването на акумулатор Spark с примери. Акумулаторите на искри са като броячите на Hadoop Mapreduce.
Научете всичко за Apache Flink и настройка на Flink клъстер в този блог. Flink поддържа обработка в реално време и периодично и е задължителна технология за големи данни за Big Data Analytics.
Тази публикация в блога обсъжда разпределеното кеширане с излъчвани променливи и ви дава началото на ефективното разпространение на големи стойности в програмирането на Spark.
CCA и CCP сертификатите от Cloudera са заменили CCDH и CCSHB изпитите. Този блог ви разказва всичко, което трябва да знаете за новите сертификати.
Тази публикация в блога обсъжда трансформации със състояние с прозорци в Spark Streaming. Научете всичко за проследяването на данни между партиди, използвайки D-потоци с пълно състояние.
Тази публикация в блога обсъжда трансформации със състояние в Spark Streaming. Научете всичко за кумулативно проследяване и повишаване на уменията за кариера в Hadoop Spark.
Технологиите Hadoop & Big Data революционизират анализа на здравеопазването. Този блог за големи данни в здравеопазването обсъжда как анализът на големи данни може да подобри медицинското обслужване.
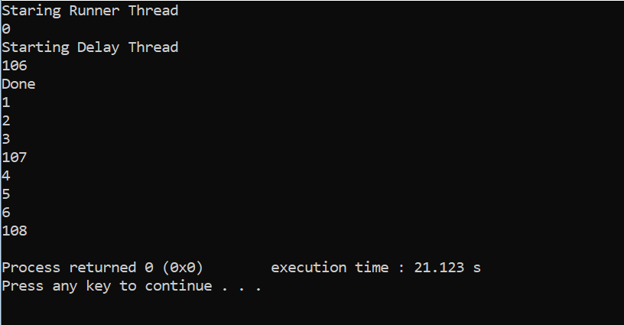
Тази публикация в блога на Hadoop Streaming е ръководство стъпка по стъпка, за да се научите да пишете програма Hadoop MapReduce в Python за обработка на огромни количества големи данни.
Този блог в Big Data Tutorial ви дава пълен преглед на Big Data, неговите характеристики, приложения, както и предизвикателствата с Big Data.
Този блог с уроци за HDFS ще ви помогне да разберете HDFS или Hadoop разпределена файлова система и нейните функции. Също така ще разгледате накратко основните му компоненти.
В този урок за Splunk разберете разликите между Splunk срещу ELK срещу Sumo Logic и определете кой от тези инструменти ви подхожда най-добре.
В този блог за случаи на използване на Splunk ще разберете как пицата на Domino's е използвала Splunk, за да получи информация за поведението на потребителите и да формулира своите бизнес стратегии.
Този урок е ръководство стъпка по стъпка за инсталиране на клъстер Hadoop и конфигуриране на един възел. Всички стъпки за инсталиране на Hadoop са за машина CentOS.
Този блог говори за различните HDFS команди като fsck, copyFromLocal, expunge, cat и др., Които се използват за управление на файловата система Hadoop.